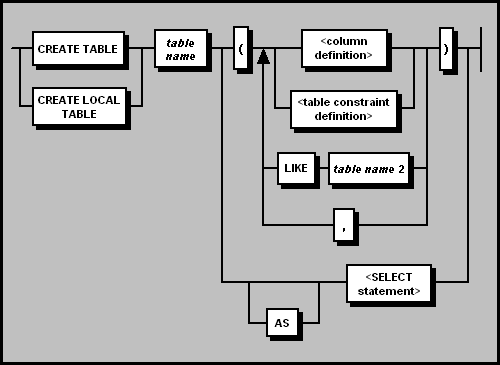
The CREATE TABLE command defines a table in the database. The CREATE TABLE statement must specify the table name, as well as the names and attributes of all columns in the table, or the names of other tables or views whose column structures will be copied in the new table. Other optional table attributes, such as PRIMARY KEY, UNIQUE, FOREIGN KEY, and NOT NULL constraints, can also be included in the definition statement. Alternatively, a SELECT statement can be used to create a new table based on the structure of the query results table, and populate the new table with the values returned by the query.
In MPP mode, the CREATE TABLE command defines a new dimension table, which is replicated across all remote nodes associated with the default partitioned table. If a CREATE TABLE...SELECT statement queries a partitioned table in MPP mode, the resulting table will also be a partitioned table.
Required Privileges
To execute the CREATE TABLE command, the user authorization must own the schema where the table will be created, possess the OWNER privilege on the schema, or possess DBA privileges.
If a domain is referenced in the CREATE TABLE statement, the user authorization must own the domain, own the schema that contains the domain, possess USAGE privileges on the domain, or possess DBA privileges.
Use of the FOREIGN KEY/REFERENCES clause requires that the user possess one of the following sets of privileges: REFERENCES privileges on the appropriate column(s) of the referenced table or on the schema containing the referenced table, ownership of the referenced table, ownership of or OWNER privileges on the schema containing the referenced table, or DBA privileges on the database.
If the LIKE table clause is used, the user authorization must own the specified table/view, possess OWNER privileges on the schema containing the table/view, or possess DBA privileges.
If a SELECT statement is used, for every base table or view identified in the query expression, the user authorization must own the table/view, own or possess OWNER privileges on the schema containing the table/view, possess SELECT privileges on the table/view, or possess DBA privileges.
CREATE TABLE | CREATE LOCAL TABLE
Outside of MPP mode, CREATE TABLE and CREATE LOCAL TABLE function the same way, creating a standard table. In MPP mode, the CREATE TABLE syntax creates a dimension table, which is automatically replicated across all partition nodes. To create a standard table in MPP mode, the CREATE LOCAL TABLE syntax must be used.
table name
The table name argument is an identifier that names the table uniquely
within the schema: it cannot match any other table or view name within the
current schema. Table names can be up to 128 characters long. It is strongly
recommended that none of the SAND CDBMS SQL keywords
be used as a table name, as this may cause problems when referencing the table
in certain SQL statements.
The table may be qualified by the schema to which it will belong: prefix the table name with the name of the appropriate schema followed by a period ( . ), that is, schema-name.table-name.
table name 2
The table name 2 argument is part of the optional LIKE clause, identifying
an existing table or view in the database. Each column in this table/view
will be copied in the new table, with the same name, definition, and order.
.gif)
column name
The column name argument is an identifier that names the column uniquely
within the table. Column names can be up to 128 characters long. It is strongly
recommended that none of the SAND CDBMS SQL keywords
be used as a column name, as this may cause problems when referencing the
column in certain SQL statements.
data type
This identifies a valid SAND CDBMS data type for the column. SAND CDBMS data types are described in the Data
Types section.
domain name
The domain name argument identifies the domain in which the column
values will be stored. The domain must already have been created with the
CREATE DOMAIN statement. If the domain
is not in the current schema, prefix the domain name with its schema name,
separated by a period (schema-name.domain-name).
constant
The optional DEFAULT constant argument specifies a literal value as the default for the column. A numeric value may be preceded by a unary operator (that is, a + or –) to indicate whether it is a positive or negative value. A character string or date/time literal must be surrounded by single quotation marks. The default value must be compatible with the domain/data type of the column.
special constant
The optional DEFAULT special constant argument specifies one of the special system variables supported by SAND:
- CURRENT DATE: The current date (DATE data type format)
- CURRENT SERVER: The current connection name (character string)
- CURRENT SQLID: The current schema name (character string)
- CURRENT TIME: The current time (TIME data type format)
- CURRENT TIMESTAMP: The current timestamp (TIMESTAMP data type format)
- USER: The current authorization identifier (character string)
The special constant must be compatible with the domain/data type of the column.
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier
(up to 128 characters long) designating a NOT NULL, UNIQUE, or PRIMARY
KEY constraint defined on a single column. A constraint name must be unique
within the table. It is strongly recommended that none of the SAND CDBMS
SQL keywords be used as a constraint name, as this may cause problems
when referencing the constraint in certain SQL statements.
The constraint name definition is optional. While SAND CDBMS will generate a default constraint name if one is not specified by the creator of the constraint, it is recommended that each constraint be assigned a meaningful name.
NOT NULL
The NOT NULL constraint prevents null values from being inserted or updated
into the designated column.
UNIQUE
The UNIQUE constraint prevents duplicate values from being inserted or updated
into the designated column, ensuring that each value in the column is unique
among all rows in the named table.
PRIMARY KEY
The PRIMARY KEY constraint ensures that each row of the table can be identified
uniquely. The column designated as the primary key for the table is also implicitly
UNIQUE and NOT NULL. There can be only one PRIMARY KEY constraint per table.
<column references specification>
The REFERENCES clause (FOREIGN KEY constraint) is used to enforce referential integrity—the relationship between a referencing or dependent table and a referenced or parent table. The referential integrity rule requires that, for any value in the dependent column, there must exist a row in the parent table where the value of the dependent column equals the value of the corresponding column in a UNIQUE or PRIMARY KEY of the parent table.
Column References Specification
.gif)
table name
Identifies the parent table referenced by the FOREIGN KEY constraint.
( column name )
Specifies the column in the parent table on which the FOREIGN KEY is created. If no column name is specified, the FOREIGN KEY constraint references the PRIMARY KEY column of the referenced table.
The data type of the column included in the FOREIGN KEY constraint must exactly match the data type of the corresponding column in the parent (referenced) table. The domains of the respective columns can differ, as long as the domains are defined on exactly the same data type. However, note that using a common domain can improve join performance.
If specified, the referenced column must be enclosed in parentheses.
.gif)
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier
(up to 128 characters long) designating a UNIQUE, PRIMARY KEY, or FOREIGN KEY constraint
defined on the table. A constraint name must be unique within the table. It
is strongly recommended that none of the SAND CDBMS
SQL keywords be used as a column name, as this may cause problems when
referencing the column in certain SQL statements.
The constraint name definition is optional. While SAND CDBMS will generate a default constraint name if one is not specified by the creator of the constraint, it is recommended that each constraint be assigned a meaningful name. This will result in greater intelligibility of error messages issued when constraints are violated, and make it easier to drop constraints (since this must be done by specifying the name of the constraint to be dropped).
column name list
As part of a table constraint definition, the column name list identifies
one or more columns on which a UNIQUE, PRIMARY KEY, or FOREIGN KEY is defined. Listed columns
are separated by commas, and the entire list must be enclosed in parentheses.
A maximum of 64 columns may be included in a key constraint.
In the case of a FOREIGN KEY, the number of columns and their data types must exactly match the number and types of the columns specified in the REFERENCES clause (see below).
UNIQUE
The UNIQUE constraint is used to ensure that the combination of values in
the designated column(s) is unique among all the rows in the named table:
duplicate value sets are not allowed. A given column name may not appear more
than once in the column list of the UNIQUE clause.
PRIMARY KEY
The PRIMARY KEY constraint ensures that each row of the table can be identified
uniquely. The columns participating in the primary key cannot already be part
of any UNIQUE constraints on the table. A given column name may not appear
more than once in the column list of the PRIMARY KEY clause. There can be
only one PRIMARY KEY constraint per table.
FOREIGN KEY
The FOREIGN KEY constraint is used to enforce referential integrity—the relationship between a referencing or dependent table and a referenced or parent table. The referential integrity rule requires that, for any value in the dependent column(s), there must exist a row in the parent table where the value of the dependent column(s) equals the value of the corresponding column(s) in a UNIQUE or PRIMARY KEY of the parent table.
Table References Specification
.gif)
table name
Identifies the parent table referenced by the FOREIGN KEY table constraint.
column name list
The column name list identifies one or more columns in the table referenced by the FOREIGN KEY table constraint. Listed columns are separated by commas, and the entire list must be enclosed in parentheses. The referenced columns must comprise either a UNIQUE or PRIMARY KEY constraint. If no column list is specified, the FOREIGN KEY constraint references the PRIMARY KEY column(s) of the referenced table.
The LIKE clause is used to create a new table with the same definition as an existing table. The columns of the table will have exactly the same names and domains/data types as the source table or view. However, none of the constraints existing on the source table and columns will exist in the new table. Data from the source table is not transferred to the new table.
Multiple LIKE clauses can be included in a CREATE TABLE statement; they may be placed anywhere in the list of column definitions, separated by commas, to reproduce another table or view 's column specifications within the new table.
The CREATE TABLE...SELECT statement executes a query whose output table provides the structure for the table being defined, and whose return values populate the new table. Each value expression in the SELECT list must have a name or alias defined. If an ORDER BY clause is included, a FETCH FIRST...ONLY clause must be present as well or else the ORDER BY clause will be ignored. Otherwise, any legal query expression can appear as the SELECT clause.
Refer to the description of the SQL SELECT command for further details.