The ALTER TABLE statement is used to alter the structure
of an existing table by adding a new column, creating, dropping, disabling, or enabling integrity
constraints, renaming a column, enabling record appending for the table, or
renumbering the records in the table. In addition, an existing table can be converted into a dimension table for a partitioned (fact) table. Since the original table is not recoverable
after a COMMIT command is executed, the ALTER
TABLE command should be used carefully.
In SAND CDBMS, each ALTER TABLE statement can specify
only one action (ADD or DROP a column definition, ADD, DROP, DISABLE, or ENABLE a particular constraint,
RENAME a column, ENABLE or DISABLE record APPENDing, convert to a dimension table, or EXECUTE RENUMBER)
to be performed on a table. To specify more than one table alteration action,
use multiple ALTER TABLE statements. In the case of DISABLE /ENABLE CONSTRAINTS, the command applies to all constraints on the table.
Required Privileges
DBA privileges are required to renumber the records in a table.
To alter a table otherwise, the user authorization must own
the table, own or possess OWNER privileges on the schema to which the table
belongs, or possess DBA privileges.
If a column is being added, the user authorization must own
any domain that is referenced, own the schema to which the domain belongs,
possess USAGE privileges on the domain, or possess DBA privileges.
If a foreign key is specified, the user must possess REFERENCES privileges on the appropriate columns of the referenced table, ownership of the referenced table, OWNER privileges on or ownership of the schema to which the referenced table
belongs, or DBA privileges.
If a table is designated a dimension table, the users defined for the connections to the remote nodes must own or possess OWNER privileges on the schema where the table will be replicated, or possess DBA privileges.
Syntax
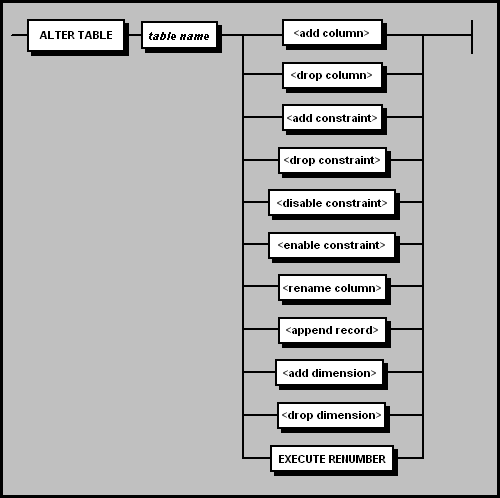
table name
The table name argument identifies an existing table. If the table
is not in the current schema, prefix the table name with the name of the appropriate
schema followed by a period ( . ), that is, schema-name.table-name.
ADD COLUMN Clause
.gif)
column name
The column name argument specifies the name of the new column being added
to the table. The new column name cannot duplicate a column name that already
exists in the table. It is strongly recommended that none of the SAND CDBMS SQL keywords be used as a column name, as this may cause problems
when referencing the column in certain SQL statements.
data type
This argument identifies a valid SAND CDBMS data type. SAND CDBMS
data types are described in the Data
Types section.
domain name
The domain name argument identifies a domain in which the column values
will be stored. The domain must already have been created with the CREATE
DOMAIN statement. If the domain is not in the current schema, prefix the
domain name with its schema name, separated by a period (schema-name.domain-name).
constant
The optional DEFAULT constant argument specifies a literal value as the default for the column. A numeric value may be preceded by a unary operator (that is, a + or –) to indicate whether it is a positive or negative value. A character string or date/time literal must be surrounded by single quotation marks. The default value must be compatible with the domain/data type of the column.
special constant
The optional DEFAULT special constant argument specifies one of the special system variables supported by SAND:
- CURRENT DATE: The current date (DATE data type format)
- CURRENT SERVER: The current connection name (character string)
- CURRENT SQLID: The current schema name (character string)
- CURRENT TIME: The current time (TIME data type format)
- CURRENT TIMESTAMP: The current timestamp (TIMESTAMP data type format)
- USER: The current authorization identifier (character string)
The special constant must be compatible with the domain/data type of the column.
ADD COLUMN Constraint Clause
.gif)
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier
(up to 128 characters long) identifying a NOT NULL, UNIQUE, PRIMARY KEY, or FOREIGN KEY constraint defined on the added column. The constraint name must be unique
among constraints defined on the table. It is strongly recommended that none
of the SAND CDBMS SQL keywords be used as
a constraint name, as this may cause problems when referencing the constraint
in certain SQL statements.
The use of constraint names is optional, but recommended.
NOT NULL
The NOT NULL constraint prevents null values from being inserted or updated
into the designated column. This constraint can only be included in the definition
of a new column if the affected table contains no data. If the NOT NULL constraint
is specified and the table already contains rows of data, the ALTER TABLE
statement will fail, since the new column will initially be assigned null
values.
UNIQUE
The UNIQUE constraint prevents duplicate values from being inserted or updated
into the designated column, ensuring that each value in the column is unique
among all rows in the named table.
PRIMARY KEY
The PRIMARY KEY constraint ensures that each row of the table can be identified
uniquely. The column designated as the primary key for the table is implicitly
UNIQUE and NOT NULL. The PRIMARY KEY constraint can be imposed on a new column
only if the affected table contains no data; if rows of data are present,
the ALTER TABLE statement will fail, since the new column will be assigned
null values. There can be only one PRIMARY KEY constraint per table.
<references specification>
The REFERENCES clause (FOREIGN KEY constraint) is used to enforce referential integrity—the relationship between a referencing or dependent table and a referenced or parent table. The referential integrity rule requires that, for any value in the dependent column, there must exist a row in the parent table where the value of the dependent column equals the value of the corresponding column in a UNIQUE or PRIMARY KEY of the parent table.
ADD COLUMN References Specification
.gif)
table name
Identifies the parent table referenced by the FOREIGN KEY constraint.
( column name )
Specifies the column in the parent table on which the FOREIGN KEY is created. If no column name is specified, the FOREIGN KEY constraint references the PRIMARY KEY column of the referenced table.
The data type of the column included in the FOREIGN KEY constraint must exactly match the data type of the corresponding column in the parent (referenced) table. The domains of the respective columns can differ, as long as the domains are defined on exactly the same data type.
If specified, the referenced column must be enclosed in parentheses.
DROP COLUMN Clause
.gif)
column name
This argument identifies a column to be dropped from the table.
ADD CONSTRAINT Clause
.gif)
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier
(up to 128 characters long) identifying a UNIQUE, PRIMARY KEY, or FOREIGN KEY constraint
being defined on one or more columns. The constraint name must be unique among
constraints defined on the table. It is strongly recommended that none of
the SAND CDBMS SQL keywords be used as a
constraint name, as this may cause problems when referencing the constraint
in certain SQL statements.
The use of constraint names is optional, but recommended.
column name list
As part of a table constraint definition, the column name list identifies
one or more columns on which a UNIQUE or PRIMARY KEY constraint is created.
Listed columns must be separated by commas, and the entire list must be enclosed
in parentheses. Any number of columns can be included in a key constraint.
UNIQUE
The UNIQUE constraint is used to ensure that the combination of values in
the designated column(s) is unique among all the rows in the named table:
duplicate value sets are not allowed. A given column name may not appear more
than once in the column list of the UNIQUE clause.
PRIMARY KEY
The PRIMARY KEY constraint ensures that each row of the table can be identified
uniquely. It is similar to the UNIQUE constraint in this regard, except that
null values cannot appear in any of the columns that are part of the primary
key. The columns included in the primary key cannot already be part of any
UNIQUE constraints on the table. If the PRIMARY KEY constraint is defined
on a column in which there are duplicate values, or on a set of columns whose
combination of values is duplicated in one or more table rows, the ALTER TABLE
statement will fail. A given column name may not appear more than once in
the column list of the PRIMARY KEY clause. There can be only one PRIMARY KEY
constraint per table.
FOREIGN KEY
The FOREIGN KEY constraint is used to enforce referential integrity—the relationship between a referencing or dependent table and a referenced or parent table. The referential integrity rule requires that, for any value in the dependent column, there must exist a row in the parent table where the value of the dependent column equals the value of the corresponding column in a UNIQUE or PRIMARY KEY of the parent table.
ADD CONSTRAINT References Specification
.gif)
table name
Identifies the parent table referenced by the FOREIGN KEY constraint.
column name list
The column name list identifies one or more columns in the table referenced by the FOREIGN KEY table constraint. Listed columns are separated by commas, and the entire list must be enclosed in parentheses. The referenced columns must comprise either a UNIQUE or PRIMARY KEY constraint. If no column list is specified, the FOREIGN KEY constraint references the PRIMARY KEY column(s) of the referenced table.
The data types of the columns included in the FOREIGN KEY constraint must exactly match the data type of the corresponding column in the parent (referenced) table. The domains of the respective columns can differ, as long as the domains are defined on exactly the same data type.
DROP CONSTRAINT Clause
.gif)
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier
(up to 128 characters long) identifying a named NOT NULL, UNIQUE, or PRIMARY
KEY constraint to be dropped.
DISABLE CONSTRAINT Clause
.gif)
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier (up to 128 characters long) identifying a named constraint to be disabled.
ENABLE CONSTRAINT Clause
.gif)
constraint name
Preceded by the CONSTRAINT keyword, constraint name is an SQL identifier (up to 128 characters long) identifying a named, previously disabled constraint to be enabled.
RENAME COLUMN Clause
.gif)
old column name
The first argument after the RENAME [COLUMN] keyword(s) specifies the name
of an existing column in the table.
new column name
The second argument after the RENAME [COLUMN] keyword(s) specifies the new
name for the column indicated by old column name. The new column name
cannot match any other column name within the specified table. It is strongly
recommended that none of the SAND CDBMS
SQL keywords be used as a new column name, as this may cause problems
when referencing the column in certain SQL statements.
APPEND Clause
.gif)
Add Dimension Clause
.gif)
partition name
The partitioned table with which the table being altered will be associated. This partitioned table must alteady exist. If it is not in the current schema, prefix the partitioned table name with its schema name, separated by a period (schema-name.partition-name).
Note that the ADD DIMENSION syntax is used in MPP mode, in the context of the default partitioned table. The DIMENSION OF partition name syntax can be used either in or outside of MPP mode.
DROP DIMENSION Clause
.gif)
ADD [COLUMN]
This clause adds a new column to the named table, positioned
to the right of existing columns. A domain name or data type
must be declared for the new column, along with field length and precision
where required.
If the table already contains rows of data, the new column is initially assigned null values, unless another default value is explicitly defined. The DEFAULT clause allows for the specification of a default value—used when a row is inserted and no value is specified for the column—in one of the following forms:
- A literal value
- A special constant (such as USER or CURRENT DATE)
- A null value (the implicit default value for a column)
Optionally, one or more constraints (separated by white space)
may be set on the new column. However, the new column cannot be defined as
both UNIQUE and PRIMARY KEY, nor as both NOT NULL and PRIMARY KEY. Refer to
Other Topics: Constraints for more
information about constraints.
The sample ALTER TABLE statement below adds a new data column
to the supplier table:
ALTER
TABLE supplier
ADD founded d_date
DEFAULT '1970-01-01'
CONSTRAINT date_not_null
NOT NULL;
The column name is followed by the name of a domain (d_date)
in which column values will be stored. A default value of '1970-01-01' is defined for the new column; this value will be used for any inserted record that does not have a value for the founded column.
Note that the NOT NULL constraint on
the founded column is given a descriptive name. This practice is recommended,
as it facilitates the dropping of the constraint later on (the constraint
name must be specified when dropping a constraint).
DROP [COLUMN]
This will remove the designated column, along with its contents,
from the table. A column cannot be dropped if it is the only column in a table. If the column is referenced by one or more other objects, such as views or table constraints, the dependent object(s) will have to be dropped before the column can be removed. The CASCADE option automatically attempts to drop the column's dependent object(s) along with the column. The RESTRICT option, which is the default behavior, prevents the column from being dropped if any dependent object exists.
The following statement illustrates the DROP [COLUMN] clause:
ALTER TABLE products
DROP comments;
This command results in the comments column, and whatever
values it contains, being removed from the products table. (Note that, since the RESTRICT option is the implicit default, this
DROP [COLUMN] action would be disallowed if the comments column is
referenced in a view definition or is part of a table constraint.)
ADD [CONSTRAINT]
This clause adds a UNIQUE, PRIMARY KEY, or FOREIGN KEY constraint to the table.
The constraint
name can be up to 128 characters long and must be unique among all constraints
defined on the table. All other restrictions on database object names apply
to the constraint name (consult SAND CDBMS SQL Database Objects and Language Elements: Object Names for more information about database object names.) While SAND CDBMS
will generate a default constraint name if one is not specified by the creator
of the constraint, it is strongly suggested that each constraint be assigned
a meaningful name. This will result in greater intelligibility of error messages
issued when constraints are violated, and make it possible to drop constraints (since this must be done by specifying the name of the constraint).
Only one PRIMARY KEY can be defined per table, and it cannot include any columns that are already part of a UNIQUE key. Refer to the Other Topics: Constraints section for more information about table constraints.
The following example adds a PRIMARY KEY constraint to the
e_no field in the employee table:
ALTER TABLE employee
ADD CONSTRAINT prim_key PRIMARY KEY (e_no);
The PRIMARY KEY constraint is named (prim_key) to
make it easier to drop at some later point, if desired.
DROP CONSTRAINT
This option is used to remove a UNIQUE, PRIMARY KEY, or NOT
NULL constraint from a table. In order to be dropped, the constraint must
be designated by its constraint name.
For example, to drop the PRIMARY KEY constraint named prim_key
on the employee table, issue this statement:
ALTER TABLE employee
DROP CONSTRAINT prim_key;
DISABLE CONSTRAINT
This option is used to disable either a specific UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK, or NOT NULL constraint on a table, or else all constraints defined on the table. It is intended for situations where it may be desirable to disable one or more constraints temporarily, instead of removing them entirely from the table. For example, since ndlm cannot load data into a table with constraints, this command is useful for temporarily deactivating the table's constraints so that a load process can be performed . Once the load is complete, the disabled constraints can be reactivated using the ALTER TABLE...ENABLE CONSTRAINT[S] command.
To disable a particular constraint, specify the constraint name using the ALTER TABLE...DISABLE CONSTRAINT constraint-name syntax.
To disable all constraints, use the ALTER TABLE...DISABLE CONSTRAINTS syntax.
Both types of DISABLE commands support the RESTRICT and CASCADE options.
The RESTRICT option, which is the default behavior when both RESTRICT and CASCADE are omitted, prevents a UNIQUE or PRIMARY KEY constraint from being disabled if it is referenced by one or more enabled FOREIGN KEY constraints.
The CASCADE option attempts to disable all FOREIGN KEY constraints that reference the UNIQUE or PRIMARY KEY constraint before attempting to disable the UNIQUE or PRIMARY KEY constraint. If the CASCADE option fails, all the constraints that were supposed to be disabled will remain enabled.
For example, to disable (rather than drop entirely) the PRIMARY KEY constraint named prim_key on the employee table, issue this statement:
ALTER TABLE employee
DISABLE CONSTRAINT prim_key;
Since the RESTRICT option is implicit, if any other table references this PRIMARY KEY constraint as part of a FOREIGN KEY constraint, the ALTER TABLE...DISABLE CONSTRAINT command will fail.
Another example below shows how all constraints on a table can be disabled with a single ALTER TABLE command. Furthermore, the presence of the CASCADE keyword means that if other tables have FOREIGN KEY constraints dependent on a key constraint on this table, an attempt will be made to disable the FOREIGN KEY constraints before disabling the current table's constraints:
ALTER TABLE employee
DISABLE ALL CONSTRAINTS CASCADE;
ENABLE CONSTRAINT
This option is used to enable either a specific constraint or all constraints defined on the table, previously disabled with the ALTER TABLE...DISABLE CONSTRAINT[S] command.
Note that enabling a constraint may fail if data in the table violates the constraint. Also, enabling a FOREIGN KEY may fail if the referenced constraint is disabled.
To enable a particular disabled constraint, specify the constraint name using the ALTER TABLE...ENABLE CONSTRAINT constraint-name syntax.
To enable all previously disabled constraints, use the ALTER TABLE...ENABLE CONSTRAINTS syntax.
Both types of ENABLE commands support the RESTRICT and CASCADE options.
The RESTRICT option, which is the default behavior when both RESTRICT and CASCADE are omitted, prevents a FOREIGN KEY constraint from being enabled if it references a disabled UNIQUE or PRIMARY KEY constraint.
The CASCADE option attempts to enable a PRIMARY KEY or UNIQUE constraint, and then enable all disabled FOREIGN KEY constraints that reference the PRIMARY KEY or UNIQUE constraint. If the CASCADE option fails, all the constraints that were supposed to be enabled will remain disabled.
For example, to enable the constraint named for_key on the employee table (assuming it was disabled previously), issue this command:
ALTER TABLE employee
ENABLE CONSTRAINT for_key RESTRICT;
The RESTRICT keyword in the above command prevents the for_key (foreign key) constraint from being enabled if it references a disabled PRIMARY KEY or UNIQUE constraint in another table.
The following command enables all disabled constraints on the inventory table with the CASCADE option:
ALTER TABLE inventory
ENABLE CONSTRAINTS CASCADE;
Here, any disabled PRIMARY KEY or UNIQUE constraint on the table will be enabled, followed by all disabled FOREIGN KEYs that reference them, since CASCADE is specified. If CASCADE was omitted, the disabled FOREIGN KEYs would have to be enabled separately for each applicable table.
Note that if the inventory table itself contains a disabled FOREIGN KEY that references a disabled PRIMARY KEY or UNIQUE constraint on another table, that PRIMARY KEY or UNIQUE constraint would have to be enabled in a separate ALTER TABLE...ENABLE CONSTRAINT[S] statement before the FOREIGN KEY could be enabled, as CASCADE does nothing in this case.
RENAME COLUMN
This clause renames an existing column in the specified table.
The new column name can be up to 128 characters long and must be unique among
all column names in the table. All other restrictions on database object names
apply to the new column name (consult SAND CDBMS SQL Database Objects and Language Elements: Object Names
for more information about database object names.) Any column or table constraints
that were defined previously on the old column name are maintained.
In the following example, the column qoh in the inventory
table is renamed to quantity:
ALTER TABLE inventory
RENAME COLUMN qoh quantity;
ENABLE/DISABLE APPEND
The ALTER TABLE...ENABLE APPEND option turns on record appending
for the table. When this is enabled, new records added through load operations
and INSERT...SELECT statements are allocated contiguously at the end of the
table, rather than filling "holes" left by unused records.
The benefits of this option is that it prevents further fragmentation
of the table until such time as its tuples can be renumbered. If there is
a high degree of fragmentation, query performance on a table will suffer,
so it is a good strategy to run the ALTER TABLE or ALTER SESSION EXECUTE RENUMBER
command periodically as required. In practice, however, tuple renumbering
can take a significant amount of time, depending on the size of the database
and the degree of fragmentation. Until a batch window is available for the
renumbering, the ALTER TABLE...ENABLE APPEND option can be used temporarily
to prevent further degradation of performance.
One side effect of turning on the APPEND option is that the
database files can grow larger than usual.
To turn off record appending, execute the ALTER TABLE...DISABLE
APPEND command.
The following ALTER TABLE statement enables record appending
for the transaction table:
ALTER TABLE transaction
ENABLE APPEND;
The following command disables record appending for the same
table if it had been enabled previously:
ALTER TABLE transaction
DISABLE APPEND;
Add Dimension Clause
The "add dimension" option is used to convert a standard table into a dimension table related to an existing partitioned table (a "fact table" in data warehousing terms). When converted in this way, the table structure of the dimension will be copied to the same schema on each node defined for the partitioned table. If the converted table contains records, these records can be subsequently loaded into all remote dimension tables using the REFRESH DIMENSION TABLE command.
There are two syntaxes for this functionality:
- ADD DIMENSION
- DIMENSION OF partition-name
The ADD DIMENSION syntax is used in MPP mode only. Since MPP mode entails a default partitioned table, no table needs to be specified. The table being altered will become a dimension table for the user's default partitioned table.
On the other hand, the DIMENSION OF partition name syntax specifies a partitioned table, which is necessary when not in MPP mode. This syntax can also be used in MPP mode to specify a partitioned table that is not the user's default.
Note that the same schema containing the converted table must exist on each node where the table will be copied, and the authorizations associated with the connections to those nodes must have at least CREATE privileges on the schema, otherwise the ALTER TABLE command will fail.
The following sample command in MPP mode converts a standard table named dim_emp_location to a dimension table associated with partitioned table part1 (assuming this is the user's default partitioned table):
ALTER TABLE dim_emp_location
ADD DIMENSION;
Alternatively, if the user is not in MPP mode, the following command can be used to convert table dim_emp_location to a dimension table associated with the specified partitioned table (part1):
ALTER TABLE dim_emp_location
DIMENSION OF part1;
DROP DIMENSION
The "drop dimension" option is used to revert a dimension table back to a standard table. After this command is executed, any changes to the former dimension table on the head node will no longer propagate to the corresponding table on each partition node. Other than this, the "drop dimension" action does not affect the corresponding remote tables.
For example, to convert a dimension table named dim_emp_location back to a standard table, issue this statement:
ALTER TABLE dim_emp_location
DROP DIMENSION;
EXECUTE RENUMBER
This option initiates internal renumbering of the records
in the specified table. This renumbering action removes gaps in the tuple
bitmap for the table, accumulated over time by the periodic deletion and insertion
of records. The end result of the renumbering is a physically smaller and
more efficient bitmap, which can significantly improve query performance if
the table is relatively large.
Note that renumbering cannot be performed when there are
active transactions. This means that the EXECUTE RENUMBER command must be
issued at the start of a new transaction, either immediately after a COMMIT
or ROLLBACK command, or just after connecting to the database.
As an alternative to the ALTER TABLE...EXECUTE RENUMBER command,
which operates on a single table only, the ALTER SESSION EXECUTE RENUMBER
command can be used to renumber the records for all tables in the database.
However, keep in mind that tuple renumbering can be an expensive operation,
in terms of both time and system resources. Database administrators should
carefully consider the available batch window before starting any renumbering
operations, especially global renumbering.
In the following example, the records in the transaction
table will be renumbered:
ALTER TABLE transaction
EXECUTE RENUMBER;