The MATCHES predicate defines a search within a text column (a column defined on a text-search-enabled BLOB domain), allowing a user to locate specific content within the textual data. SAND CDBMS supports the following types of search on text columns:
- Searching for exact matches for words and phrases
- "Phonic" searches (that is, "sounds like" matching based on double metaphone encoding)
- "Fuzzy" searches for similar but not identical strings (that is, "spelled like" matching, allowing for typing errors and so on)
- Proximity searches for one word within or beyond a specified distance from another
- "Concept" searches for synonyms using a built-in thesaurus
- "Stem" searches that locate all words sharing a common stem with the search term
- "Between" searches for all numbers within a
specified range.
Any of these search types can be combined within the same MATCHES expression, and the MATCHES predicate can be combined with other standard SQL SELECT predicates, by means of the Boolean operators AND, OR, and NOT.
An extension to the text analytics functionality is the ability to filter search results according to relevance. The "bag of words" search option allows users to specify a list of words, phrases, and/or text search expressions (PHONIC, FUZZY, STEM, and so on) as search terms; the numeric relevance of each searched record to the collection of search terms will be calculated, and the records can be filtered using a specified threshold for relevance.
Refer to the Filtering Text Searches on Relevance ("Bag of Words" Search) section below for further information.
Enabling and Disabling Text Analytics Functionality
The MATCHES predicate can only be used to query columns defined on domains of the BLOB data type that have a dictionary associated with them. The dictionary can be any standard user-created SAND domain with the data type VARCHAR(4056) and an uppercase collation; to enable "concept" synonym searches, however, the built-in thesaurus dictionary SYSTEM."_SYNDICT" must be used.
To link a BLOB domain to a dictionary, use the ALTER DOMAIN...ADD DICTIONARY command. This populates the dictionary domain with an index containing all the words in the altered BLOB domain. In this context–with a few special exceptions, described below–a "word" can be defined as a character string that contains no whitespace. Note that punctuation (other than the apostrophe in the n't contraction and the 's suffix) is ignored when creating the dictionary, and that recognized multi-part names such as "Van Halen" or "Bin Laden" are indexed as single words.
In order to enable stem searching, the optional argument ENGLISH_STEM must be included in the ALTER DOMAIN command, as described below.
Before the ALTER DOMAIN command can be executed to add (or drop) a dictionary, the user must have an exclusive connection to the database. To establish an exclusive connection, execute the following command (DBA privileges are required):
SET TRANSACTION ISOLATION LEVEL EXCLUSIVE [ IMMEDIATE ];
Then issue the ALTER DOMAIN...ADD DICTIONARY command, specifying the name of the VARCHAR(4056) domain to be used for the dictionary. To enable concept (synonym) searches, include the SYSTEM."_SYNDICT" argument instead of the name of a user-created dictionary domain. To enable stem searches, include the ENGLISH_STEM argument.
ALTER DOMAIN <BLOB domain name> ADD DICTIONARY
{ <dictionary domain name> | SYSTEM."_SYNDICT" } [ ENGLISH_STEM ];
To restore the domain to standard use by dissociating the dictionary from it and disabling text analytics functionality, use the following command (an exclusive connection to the database–and therefore DBA privileges–is required):
ALTER DOMAIN <domain name> DROP DICTIONARY;
Each ALTER DOMAIN command executes an implicit COMMIT when it completes, ending the current, exclusive transaction.
Command Syntax for Text Analytics
The MATCHES (text analytics) syntax is as follows:
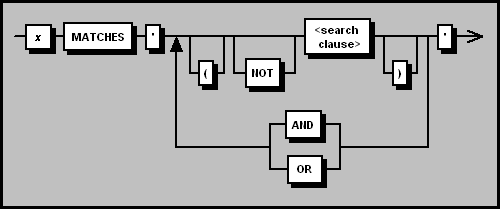
x
The column containing the textual data that will be searched. This column
must be defined on a text-search-enabled BLOB domain.
' '
The entire clause after the MATCHES keyword, describing the actual parameters
of the search, must be contained within single quotation marks.
( )
Optionally, the search clause(s) can be enclosed by any number of matching
parentheses, either to force a specific order of processing (clauses within
the innermost parentheses are evaluated before all others), or simply to improve
the readability of complex expressions.
Note that all of the search conditions after the MATCHES keyword can also be contained in parentheses–that is, x MATCHES ('<text search conditions>')–though this has no effect on processing.
NOT, AND, OR
The order in which Boolean operators are evaluated within the expression is
as follows: NOT, AND, then OR. If required, parentheses can be used to override
the order of evaluation, since the contents of parentheses are always evaluated
first.
.gif)
( )
Each search expression (or pair of proximate search expressions) can be optionally
enclosed by matching parentheses. These can be used to force the order of
processing (expressions within the innermost parentheses are evaluated before
all others), or simply to improve the readability of complex search patterns.
BEFORE/n
AFTER/n
NEAR/n
NOTNEAR/n
The keywords that define the proximity relationships between pairs of search
terms. The n specifies the maximum number of words (character strings
containing no whitespace) that can separate the two search terms, and must
be a value from 1 to 9. Note that there must be no spaces
between the keyword and "/n".
.gif)
( )
Optionally, the search expression can be contained in matching parentheses.
" "
The search term must be surrounded by double quotation marks.
SEARCH
The SEARCH keyword specifies a search for an exact word or phrase in a text
field. The SEARCH keyword is optional, as this is the default search mode.
PHONIC
The PHONIC keyword specifies a "sounds like" search, which looks
for all words that sound similar to the search term.
FUZZY/n
The FUZZY/n keyword specifies a "spelled like" search, which
looks for words that have a spelling similar to the search term. The n
indicates the maximum number of permitted spelling differences (added, deleted,
or changed characters) from the search word, and must be a value from 1
to 9. Note that there must be no whitespace between FUZZY and
/n.
CONCEPT
The CONCEPT keyword specifies a synonym search, which looks for all synonyms
of the search word, as well as the search word itself. This type of search
can be executed only when the SYSTEM."_SYNDICT" thesaurus has been
associated with the BLOB domain.
When the CONCEPT search is used, the search term should consist of a single word.
STEM
The STEM keyword specifies a search for all words having the same stem (that
is, base form without prefix or suffix) as the search term. This type of search
can be executed only if the ENGLISH_STEM option was included in the ALTER
DOMAIN...ADD DICTIONARY statement that associated a dictionary with the BLOB
domain.
When the STEM search is used, the search term should consist of a single word.
BETWEEN x AND y
The BETWEEN keyword specifies a numeric range search, where x and y
are the numeric values that define the inclusive bounds for the search. The
values for x and y can be integer or decimal; base 10 exponential
notation is also accepted. The two values can be specified in either order;
that is, x need not be less than y.
Quotation marks must not enclose either x or y, as they are numbers, not string literals.
search term
The string literal word or phrase that will form the basis of the text search.
The following wildcard characters can be used in text searches:
_
(underscore) for a single character-and-
%
(percent) for a string of 0 or more characters.
If their literal meaning as punctuation is intended, these characters can be "escaped" by preceding them with a backslash ( \ ).
Note that the wildcard characters only have special meaning when searching. When values are being inserted into a table, these characters always have their literal meaning as punctuation, and do not have to be backslash-escaped.
To search for a particular string (either a single word or an entire phrase) in a text field, include a basic search clause after the MATCHES keyword. The basic search clause consists of the SEARCH keyword (optional) followed immediately by the desired search term enclosed within double quotation marks (" "). The entire clause must be enclosed in single quotation marks (' ').
SELECT <select list>
FROM <table list>
WHERE <column> MATCHES '[ SEARCH ] "<search term>" ';Example
SELECT c1 FROM t1 WHERE c1 MATCHES '"abc"';
-or-
SELECT c1 FROM t1 WHERE c1 MATCHES 'SEARCH "abc" ';
Note:
If stemming has been enabled (that is, if the ENGLISH_STEM argument has been included in the ALTER DOMAIN...ADD DICTIONARY command), a basic text search for an exact match will return all words that share the search term as a stem. For example, a search for "walk" will also return "walks", "walked", "walking" and so on. Refer to the "STEM Search" section below for further information.
A phonic search finds all words that sound like a specified word. To enable phonic searching, include the PHONIC keyword before the search term.
SELECT <select list>
FROM <table list>
WHERE <column> MATCHES 'PHONIC "<search term>" ';Note that if the search term contains more than one word, each word is considered separately. That is,
'PHONIC "gray cat"'
would produce all the phrases where any phonic equivalent of "gray" is followed by any phonic equivalent of "cat".
Example
SELECT c1 FROM t1 WHERE c1 MATCHES 'PHONIC "gray" ';
This would return rows where t1.c1 contains the word "grey" as well as "gray".
A fuzzy search finds words whose spellings are similar to each other, as determined with reference to the specified Levenshtein distance value (that is, the number of added, deleted or changed letters required to differentiate the words). To enable fuzzy searching, include the FUZZY keyword followed by the maximum allowable Levenshtein distance (/n) before the search term using the following syntax:
SELECT <select list>
FROM <table list>
WHERE <column> MATCHES 'FUZZY/n "<search term>" ';The Levenshtein distance value (n) must be a number from 1 to 9.
Words in the BLOB text that have n or less differences from the search term will be considered a match.
Example
SELECT c1 FROM t1 WHERE c1 MATCHES 'FUZZY/1 "gray"';
This would return rows where t1.c1 contains the words "grab", "fray", "ray", "grady" and so on, as well as the search term "gray".
When the SYSTEM."_SYNDICT" thesaurus has been associated with a domain, it is possible to search for a word along with all its synonyms by including the CONCEPT keyword in the command.
SELECT <select list>
FROM <table list>
WHERE <column> MATCHES 'CONCEPT "<search term>" ';Note that the concept search can only be performed on a single word. If a multi-word phrase is specified as the search term, the concept search will search only for the first word and ignore the rest.
Sets of synonyms follow two rules:
- A word is always a synonym for itself. This means that a concept search for a word that is not in the thesaurus searches for that word and that word only.
- If word a is a synonym of word b, then word b is a synonym of word a. This means that if "nonexistence" is a synonym of "nonbeing", and a concept search for "nonbeing" will find "nonexistence", then a concept search for "nonexistence" will find "nonbeing". Thus any two words are either synonyms of each other or not synonyms at all.
Example
SELECT c1 FROM t1 WHERE c1 MATCHES 'CONCEPT "large" ';
This would return all records where t1.c1 contains the words "big", "huge", and so on, as well as "large".
When the English_Stem argument has been specified in the ALTER DOMAIN...ADD DICTIONARY command for the BLOB domain, it is possible to search for all words having the same stem (that is, base component, without suffix or, in some cases, prefix) as the specified search term by including the STEM keyword in the command.
SELECT <select list>
FROM <table list>
WHERE <column> MATCHES 'STEM "<search term>" ';Currently, only single words may be specified as the search term in a stem search. If a multi-word phrase is specified, only the first word will be searched for, and the rest will be ignored. The specified search word does not need to be a stem itself.
If a stem search is attempted on a domain for which the option has not been enabled, an error is returned.
Note that a prefix is recognized as such if and only if it ends with a dash (-), for example, "pre-" in "pre-selected" or "quasi-" in "quasi-legal". Similarly, certain word endings are regarded as a suffix only if it is preceded by a dash, for example, "-esque" in "Beatles-esque".
Example
SELECT c1 FROM t1 WHERE c1 MATCHES 'STEM "scheduled" ';
This would return all records where t1.c1 contains the words "schedule", "schedules", "scheduling", "re-schedule", and so on, as well as "scheduled".
A numeric range search finds all numbers between the two specified numeric values, inclusive, in the textual data.
SELECT <select list>
FROM <table list>
WHERE <column> MATCHES 'BETWEEN <x> AND <y> ';The specified range numbers <x> and <y> can be integer or decimal, and can be represented in exponential form (base 10 only). They must not be contained in quotation marks, otherwise they will be interpreted as strings rather than numbers.
Example
SELECT c1 FROM t1 WHERE c1 MATCHES 'BETWEEN -3.1 and 8.453e2 ';
This would return rows where t1.c1 contains any numbers between -3.1 and 845.3 inclusive. So that could include:
- -2
- 0
- 10.5
- 9.98e1
- 845.3
A proximity search looks for a specified text string within or beyond a specified distance (measured in words) from another string. There are four types of proximity search: BEFORE, AFTER, NEAR and NOTNEAR. Note that either or both of the search terms in the proximity search may be any type of non-Boolean search expression.
In each of the following cases, the specified distance n must be a number from 1 to 9.
BEFORE
SELECT <column list> FROM <table list> WHERE
<column> MATCHES '("<search term 1>") BEFORE/n ("<search term 2>")' ;Searches for <search term 1> up to n words before <search term 2>
AFTERSELECT <column list> FROM <table list> WHERE
<column> MATCHES '("<search term 1>") AFTER/n ("<search term 2>")' ;Searches for <search term 1> up to n words after <search term 2>
NEARSELECT <column list> FROM <table list> WHERE
<column> MATCHES '("<search term 1>") NEAR/n ("<search term 2>")' ;Searches for <search term 1> within n words of <search term 2> (<search term 1> may be before or after <search term 2>)
NOTNEARSELECT <column list> FROM <table list> WHERE
<column> MATCHES '("<search term 1>") NOTNEAR/n ("<search term 2>")' ;Searches for instances of <search term 1> that do not occur within n words of an instance of <search term 2>
Nesting of Text Searches Within Proximity Searches
Proximity searches (NEAR, BEFORE, AFTER, and NOTNEAR) support some nesting, in that another type of text search may occur inside the proximity search. In this case, the entire expression must be enclosed by single quotation marks.
For example:
SELECT <column> FROM <table> WHERE <column> MATCHES
'(FUZZY/n "<search term 1>") BEFORE/n (PHONIC "<search term 2>")';Any type of text search, with the exception of the Boolean type, can be nested within a proximity search. This includes CONCEPT and STEM searches.
Example
SELECT c1 FROM t1 WHERE c1 MATCHES '(("cat") NEAR/5 ("dog")) BEFORE/3 ("elephant")';
Here the position of the first word ("cat") in the "NEAR" search would be used to determine the distances in the "BEFORE" search. In other words, all instances of "cat" would be returned that have "dog" within 5 words, and are at most 3 words before "elephant". Specific instances of "dog" or "elephant" would not be returned.
Complex search expressions can be constructed using the three standard Boolean operators AND, OR and NOT in conjunction with SAND CDBMS text search expressions. The entire Boolean search expression must be enclosed in single quotation marks.
The order in which Boolean operators are evaluated within an expression is as follows, unless altered by the presence of parentheses: NOT, AND, then OR. Parentheses can be placed around individual predicates, groups of predicates, and even the whole Boolean value expression; the predicate(s) enclosed by parentheses will be evaluated first.
AND
Text search expressions of any type can be combined with the AND operator:'("<text search expression1>") AND ("<text search expression2>")'
The result is all records that satisfy both <text search expression1> and <text search expression2>.
OR
Text search expressions of any type can be combined with the OR operator:'("<text search expression1>") OR ("<text search expression2>")'
The result is all records that satisfy either <text search expression1> or <text search expression2> (or both).
NOT
Text search expressions of any type can be negated with the keyword NOT'NOT (<text search expression>)'
The result is all the records (of the set being searched) that do not satisfy <text search expression>.
Filtering Text Searches on Relevance ("Bag of
Words" Search)
Another way to search text involves calculating the numeric relevance of each searched record to a list of search terms, and filtering those records according to a user-defined threshold for relevance. This type of search is called a "bag of words" search; it operates in a manner similar to some of the modern Internet search engines, like Google.
The "bag of words" search is performed using the RELEVANCE() function, which takes the text column name and a list of search terms as parameters, then calculates and returns a relevance score for each record in the search. By including RELEVANCE() in a Boolean condition in the WHERE clause of a text analytics query, the relevance scores can be used to filter the results however desired.
The search terms supplied to the RELEVANCE() function can be any combination of single words, exact phrases, and text analytics expressions (PHONIC search, FUZZY search, STEM search, and so on).
Syntax
RELEVANCE( <column>, '<list of search terms>' )
where:
- <column> is the text column that will be searched.
- '<list of search terms>' is the list of search terms (the "bag of words"). Almost any non-alphanumeric, printable ASCII character(s) can be used to separate the items in the list. Typical list item delimiters include space characters, commas, and/or semicolons. Characters that cannot be used as delimiters, since they have special meaning in the search list syntax, are the open bracket ( [ ), double quotation marks ( " ), and the forward slash ( / ).
There are three categories of search terms:
- single word : an individual word, for example, warehouse
- exact phrase : a precise arrangement of two or more words, surrounded by double quotation marks, for example, "operational data stores"
- text search expression : any of the other text search types can be included as an item in the RELEVANCE() search list. By default, all words or phrases in the search list are searched for using the standard search method. To use other search types, such as a phonic search or proximity search, the search expression can be specified between brackets ( [ ] ). For example:
- [SEARCH "baseline"] or ["baseline"] (Note: This is the default search type for "bag of words" searches.)
- [PHONIC "morph"]
- [NOT (FUZZY/3"rigueur")]
- [CONCEPT "method"]
- [STEM "manage"]
- [BETWEEN 1 AND 9]
- ["network" NEAR/4 "storage"]
- [NOT (("disaster") BEFORE/2 ("recovery"))]
- [SEARCH "disintermediation" OR (FUZZY/1 "disk" AND PHONIC "cache" AND "online" NOTNEAR/3 "processing")]
If a search term literal contains double quotation marks ( " ), each instance of the double quotation marks must be escaped with a preceding backslash ( \ ).
Note that the entire list of search terms must be contained in single quotation marks.
Relevance Scores
The relevance score for each record, which is based on the sum of relevances for all search terms, is a real number ranging from 0 (no relevance) to 1 (maximum relevance). The relevance score for a search term is calculated according to such factors as:
- the number of times the search term appears in the text
- the weight assigned to the search term
- the length of the text
- how many records contain the search term (it is assumed that a search term appearing in very few records is likely to be more important than one appearing in many).
By comparing the output of the RELEVANCE() function to a threshold value in the WHERE clause of a query, results can be filtered according to a desired level of relevance. For example:
SELECT ... WHERE RELEVANCE(col1, 'sand magma glass') > 0.75 ;
will return records that contain reasonably relevant instances of the words "sand", "magma", and "glass".
As a further refinement, we can order the results in descending order of relevance, so that the most relevant records appear first. An example of this kind of query is the following:
SELECT * FROM (SELECT RELEVANCE(col1, 'sand magma glass') AS relevance_score, col1 FROM t1) AS t1
WHERE relevance_score > 0.75
ORDER BY relevance_score DESC ;
The unfiltered nested table expression in the SELECT statement above is required for the relevance scores to be calculated against the entire table, rather than against just the records allowed by the WHERE clause. This distinction is important because of the way that relevance scores are calculated. To illustrate, consider this query:
SELECT RELEVANCE(col1, 'sand magma glass'),
...
WHERE RELEVANCE(col1, 'sand magma glass') > 0.75 ;
The RELEVANCE() functions in the projection list and the WHERE clause will generally calculate different relevance scores for the same rows. This is because the function in the WHERE clause compares each row to the entire table to get the relevance score, while the function in the projection list compares each row against the filtered data set, usually altering the relevance.
While it is possible to execute a more simplified query like the following to sort the records by relevance:
SELECT RELEVANCE(col1, 'sand magma glass') AS relevance_score,
...
WHERE RELEVANCE(col1, 'sand magma glass') > 0.75 ORDER BY 1 DESC ;
the results will not be as accurate as those returned by the equivalent query with the nested table expression; and the differences might be confusing, as some of the returned relevance scores can be lower than the specified threshold value.
Weights
Optionally, numeric weights can be added to individual search terms to change the relative importance of those terms, which will affect the calculation of relevance scores. The larger the numeric value of the weight, the greater the relative importance of the search term; so records containing the search term should score higher for relevance, compared to the same search with a lower weight.
A weight is specified by appending a slash character and a number to the search term:
<search term>/n
where n is a nonnegative integer value
For example:
- ' random/4 access/12 memory/2 '
- ' "random access memory"/6 bank '
- ' germane/9 [SEARCH "client" AND PHONIC "sun"]/5 ["upload" NEAR/2 "speed"]/2 '
By default, if no weight is specified, a search term has a weight of 1.
Note that if a weight of 0 is specified for a search term, that term will not contribute to the relevance scores.
Wildcards
As with the other text search types, wildcard characters can be used in the "bag of words" search terms:
_ (underscore) for a single character
-and-
% (percent) for a string of 0 or more characters.
If their literal meaning as punctuation is intended, these characters can be "escaped" by preceding them with a backslash ( \ ).
Examples
The following search returns those records from text column col1 that have relevance scores greater than 0.5 in relation to the word "thimble", the phrase "art nouveau", and words that sound like "mink":
SELECT col1 FROM t1 WHERE RELEVANCE(col1, 'thimble "art nouveau" [PHONIC "mink"]') > 0.5 ;
The same query, but with weights attached to "art nouveau" and the PHONIC search, will produce different relevance scores. For this search, instances of "art nouveau" are considered much more important to the relevance calculation than words that sound like "mink", which is in turn more important than instances of "thimble". Also note that the high comparison value of 0.9 ensures that only highly relevant records will be returned by the query:
SELECT col1 FROM t1 WHERE RELEVANCE(col1, 'thimble "art nouveau"/5 [PHONIC "mink"]/2') > 0.9 ;
It should be noted that since relevance scores fall between 0 and 1 inclusive, relevance comparisons outside of this range are not very helpful. For instance, the following two queries will always return 0 records from table t1:
SELECT col1 FROM t1 WHERE RELEVANCE(col1, 'gumbo Rhine') < 0 ;
SELECT col1 FROM t1 WHERE RELEVANCE(col1, 'gumbo Rhine') > 1 ;
Conversely, the following two queries will always return every record from table t1:
SELECT col1 FROM t1 WHERE RELEVANCE(col1, 'gumbo Rhine') >= 0 ;
SELECT col1 FROM t1 WHERE RELEVANCE(col1, 'gumbo Rhine') <= 1 ;
Case
SAND CDBMS text analytics functionality is not case-sensitive.Words
For the purpose of unstructured text analytics, a word is considered to be a string containing no whitespace, except in the case of the n't contraction as described below.The Contraction "n't"
The contraction n't is indexed as a separate word. This allows an expanded search under certain circumstances:
- If the word "not" is searched for, "n't" is also returned
- If a word ending in "n't" is searched for, "<wordstem> not" is also returned, where <wordstem> is the part of the word excluding the "n't"
- If the word "n't" is searched for by itself (that is, as a three letter string), the search is not expanded to include "not"
Strings that Combine Hyphens and Numbers
Only true negative signs will be indexed as words. "9-5" will be considered as occurrences of two words, "9" and "5". However, in "9 -5" the "-5" will be considered a true negative and thus a word.Words ending in "s"
A word that ends in 's is also indexed without the "'s" so that a search for "John" will also find "John's". Note that the opposite is not true: a search for "John's" will not find "John".Words Containing Quotation Marks
If a word contains an apostrophe ( ' ), the word is indexed without the apostrophe, unless this is part of n't or 's at the end of the word; in these cases the quotation mark is retained. This means that a search for "Hawaii" will also find "Hawai'i", and vice versa.
Other Predicates: